
Recommandations et limites de la création de fentes pour l'agent virtuel
Lorsque vous activez l'agent virtuel, vous pouvez l'utiliser pour configurer des emplacements alimentés par l'IA. Avant de configurer vos emplacements et types d'emplacements avec l'agent virtuel, examinez les limitations, les considérations et les conseils que les développeurs de Genesys recommandent pour les emplacements LLM (Large Language Model). Le tableau suivant définit les types de fentes disponibles avec l'Agent Virtuel.
| Type de fente | Description | Exemples |
|---|---|---|
| Séquence numérique |
Séquences numériques d'une longueur fixe fournies par les participants au robot. |
|
| Combinaison lettre-nombre |
Séquences alphanumériques de longueur fixe fournies par les participants au robot. |
|
| Free-form |
Une séquence de forme libre fournie par les participants du robot avec une description donnée. |
|
Les sections suivantes décrivent les limites des slots, des informations sur la manière dont ces slots gèrent la confirmation et la négation explicites par le bot participant, ainsi que des exemples spécifiques.
Emplacements numériques
Utilisez ce type de slot lorsque vous souhaitez que le robot ne prenne en compte que les caractères numériques dans les séquences extraites. Le robot ne reconnaît pas les autres caractères.
- Les entités qui dépassent la valeur maxLength définie ne sont pas acceptées. Par exemple, si la valeur de l'entité est "123456", que la longueur maximale est fixée à 7 et que le client dit "78", alors comme l'entité nouvellement extraite est "12345678" et que la longueur est maintenant de 8, le robot traite la nouvelle entité comme un noMatch et conserve le reste comme "123456".
- Correction des cas qui ne sont pas explicites ou qui se trouvent dans la partie médiane de l'entité extraite. Dans les exemples suivants, l'entité précédemment extraite était 1299554464.
Exemples de corrections de travail :- "Non, les deux derniers chiffres doivent être remplacés par 62 au lieu de 64.
- "Les deux derniers chiffres devraient être 62.
Exemple de corrections non fonctionnelles:
-
- "Pas de 62. Le LLM ne peut pas déterminer ce qu'il faut modifier.
- "Non, je voulais dire 62". Le LLM ne peut pas déterminer ce qu'il faut modifier.
- "Remplacer 55 par 44". Cette entrée est difficile à déterminer pour le LLM car elle se trouve au milieu de l'entité.
- "L'entité doit commencer par un 5. Le LLM peut ajouter un 5 au début ou corriger "1299554464" en "5299554464" comme prévu.
-
- Le LLM n'a pas de problème avec des valeurs numériques plus importantes ; cependant, cela augmente le risque d'une correction plus difficile. Les grandes valeurs numériques sont plus difficiles à corriger au début ou au milieu de la valeur. En raison de cette limitation, Genesys recommande l'utilisation de la nature multi-fentes. Ainsi, si un numéro de carte de crédit est extrait, demandez les données en tranches de 4 chiffres. Toute erreur se produit dans les quatre derniers chiffres, ce qui facilite la correction.
Les cas qui fonctionnent bien sont les suivants :
- Extraction simple de chiffres de toutes longueurs. Par exemple, "Mon numéro de carte de crédit est 0123456789012232".
- Extraction de chiffres sur plusieurs tours avec des chiffres en format lexical. Par exemple :
- Participant : "Ma carte commence par 0011" bot : "J'ai obtenu 0011 jusqu'à présent, veuillez continuer".
- Participant : "Alors 7831" bot : "J'ai obtenu 0011 7831 jusqu'à présent, veuillez continuer".
- Participant : "Seven one double oh" bot : "J'ai obtenu 0011 7831 7100 jusqu'à présent, veuillez continuer."
- Participant : "Enfin, 3333" bot : "J'ai obtenu 0011 7831 7100 3333, c'est correct ?"
- Corrections explicites ; par exemple, "Remplacez les deux derniers chiffres de 84 par 82".
- Le LLM considère le "double" comme deux de ce qui suit ; par exemple, double 2 = 22. Le RBA devrait d'abord convertir cette réponse en 22. Le "triple"/"triple" correspond à trois de ces chiffres et le "quadruple" à quatre.
- Le LLM traite "Oh" comme "0" dans les situations attendues, et non dans les situations inattendues telles que "Oh, désolé, je voulais dire".
Emplacements pour les lettres numérotées
Utilisez ce type d'emplacement pour fournir des indications pendant l'extraction lorsque les participants utilisent des alphabets phonétiques ; par exemple, l'alphabet phonétique NATO. Par exemple, un utilisateur peut dire "a pour alpha" et le caractère extrait est "A".
- Les entités qui dépassent la valeur maxLength définie ne sont pas acceptées. Par exemple, si la valeur de l'entité est "A12345", que la longueur maximale est fixée à 7 et que le client dit "67", comme l'entité nouvellement extraite est "A1234567" et que la longueur est maintenant de 8, le robot traite la nouvelle entité comme noMatch et conserve l'entité "A12345".
- Caractères dupliqués sur plusieurs tours. Si, au tour 1, l'entité extraite est "AB78G" et que, au tour suivant, le client commence par un autre "g", le LLM peut renvoyer par erreur "AB78G" au lieu de "AB78GG".
- Corrections ambiguës. Par exemple, "Non, j'ai dit AZ". Une correction ambiguë peut se produire si, au tour 1, le client a dit "A pour pomme, C 72", ce qui a été extrait comme "AC72" ; au tour suivant, il pourrait faire une correction difficile telle que "Non, j'ai dit AZ".
- Le LLM n'a pas de problème avec des valeurs alphanumériques plus grandes ; cependant, cela augmente le risque de correction plus difficile. Les grandes valeurs numériques sont plus difficiles à corriger au début ou au milieu de la valeur. En raison de cette limitation, Genesys recommande l'utilisation de la nature multi-flot, donc si un numéro de passeport est extrait, demandez les données en tranches de 3 caractères. Toute erreur se produit dans les trois derniers chiffres, ce qui facilite la correction.
Les cas qui fonctionnent bien sont les suivants :
- Extraction alphanumérique de toutes longueurs avec épellation phonétique des lettres, des lettres simplement énoncées et des chiffres. Par exemple, "Mon numéro de passeport est a pour apple, b pour beta, c pour charlie, d 8909".
- Extraction alphanumérique sur plusieurs tours avec des chiffres au format lexical, par exemple :
- Participant : "Mon numéro de membre commence par AB11" bot : "J'ai obtenu AB11 jusqu'à présent, continuez s'il vous plaît.
- Participant : "Alors c pour charlie et z pour zeta" bot : "J'ai obtenu AB11 CZ jusqu'à présent, continuez s'il vous plaît.
- Participant : "beta alpha" bot : "J'ai obtenu AB11 CZ BA jusqu'à présent, continuez s'il vous plaît.
- Participant : "Enfin, 99" bot : "J'ai AB11 CZ BA 99, c'est bien ça ?"
- Corrections explicites. Par exemple, "Non, la dernière lettre aurait dû être Z pour zeta et non pas c".
- Le LLM considère le "double" comme deux de ce qui suit ; par exemple, double 2 = 22. Le RBA devrait d'abord convertir cette réponse en 22. Le "triple"/"triple" correspond à trois de ces chiffres et le "quadruple" à quatre.
- Le LLM traite "Oh" comme "0" dans les situations attendues, et non dans les situations inattendues telles que "Oh, désolé, je voulais dire".
Machines à sous à forme libre
Utilisez ces emplacements lorsque vous souhaitez que le robot reconnaisse une description textuelle de l'entité à capturer. Par exemple, une adresse avec le nom de la rue, la ville et le code PIN.
- Adresses
- Format d'adresse selon les normes spécifiques du pays. Le participant au robot doit se fier à la description que vous lui fournissez pour s'assurer que le format est correct.
- Boîtier : La casse est généralement correcte ; cependant, l'entité extraite peut parfois être retournée en minuscules ou en majuscules.
- Emails
- Identification incorrecte des noms de domaine personnalisés dans les conversations à plusieurs tours. Les retours sont plus fréquents et plus précis lorsque les courriels sont fournis en une seule fois.
- Cas où les transcriptions ASR ne parviennent pas à convertir les tirets, les points et les traits de soulignement.
- Noms
- Caractères manquants ou réarrangés lorsque les noms longs sont épelés.
La sortie du modèle après chaque appel contient deux parties : l'entité extraite et un booléen, indiquant si l'extraction est terminée ou non, sur lequel le statut de détection de l'entité est en cours ou terminé. Pour les formes libres, le robot utilise la description fournie.
- Le modèle utilise la description pour juger si l'entité est capturée ou si des parties mentionnées dans la description sont manquantes. Une description devrait idéalement contenir ce que l'entité concerne et les autres sous-entités ou parties d'une entité qu'elle doit contenir.
- Il est également possible de passer à l'étape suivante. Si le client dit explicitement quelque chose de semblable à : "J'ai fini, c'est tout, c'est tout, je ne l'ai pas, je ne sais pas", et ainsi de suite, l'état de l'extraction passe à terminé et remplace la collecte de la sous-entité basée sur la description.
Exemples de créneaux libres : Cas où le robot peut juger correctement de l'état de détection de l'entité
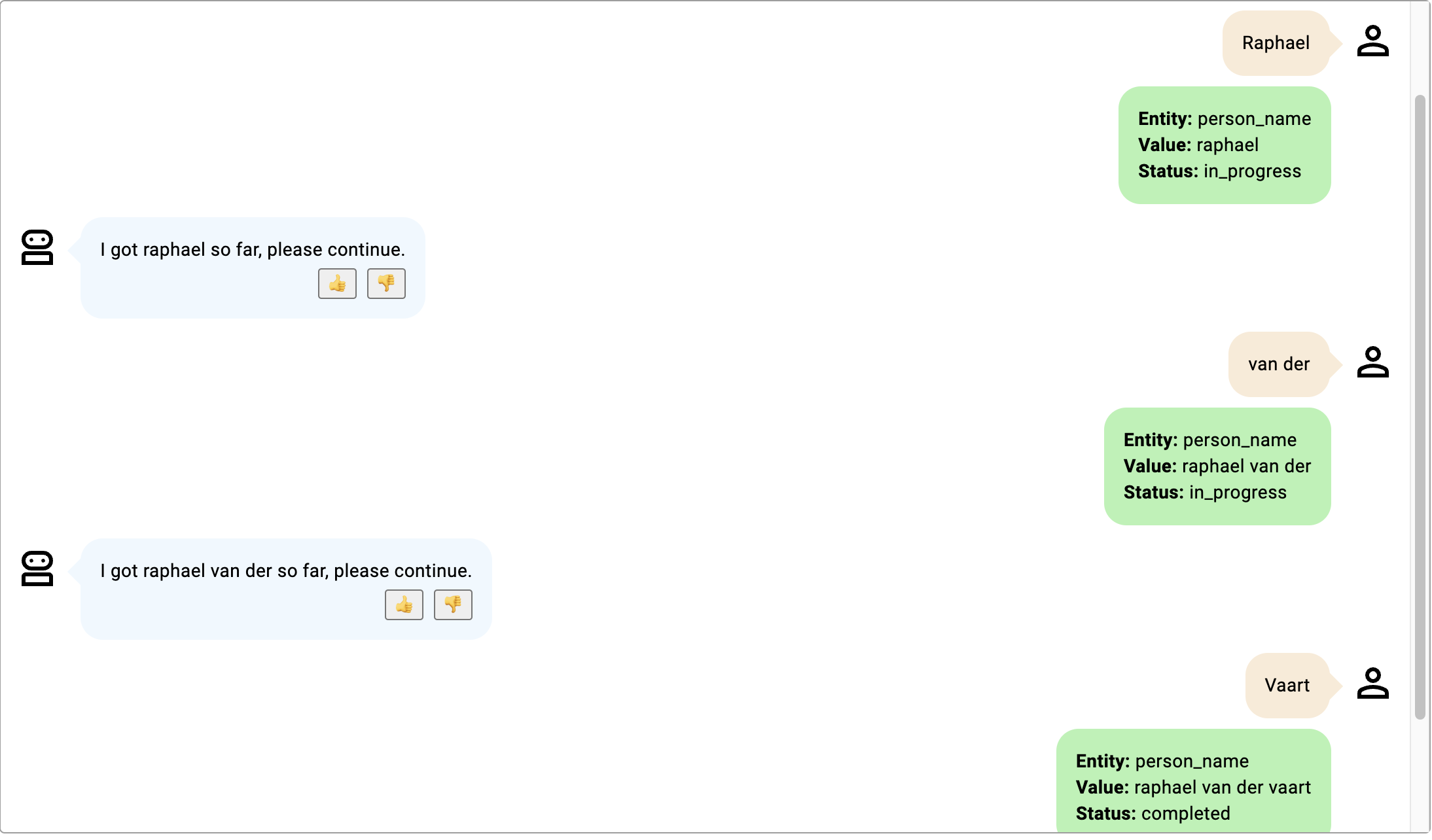
Dans ces exemples, le slot est person_name pour décrire le prénom et le nom d'une personne.
- Le bot participant mentionne spécifiquement quelle partie de l'entité est fournie.
Cliquez sur l’image pour l’agrandir.
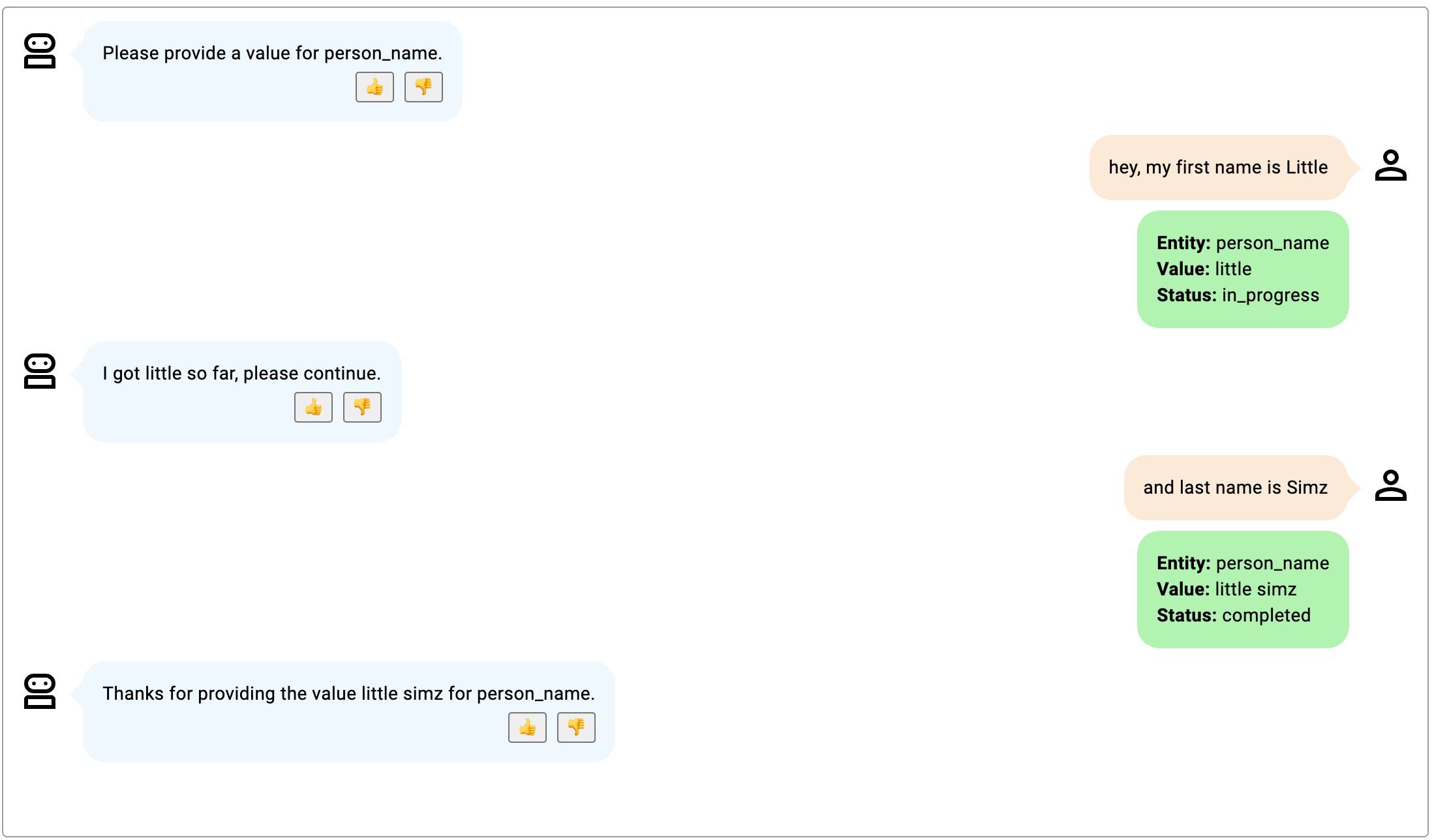
- Le participant au robot ne mentionne que la partie du nom fournie lors du tour initial ; le modèle suppose que la sous-entité suivante fournie par le participant au robot est le nom de famille.
Cliquez sur l’image pour l’agrandir.
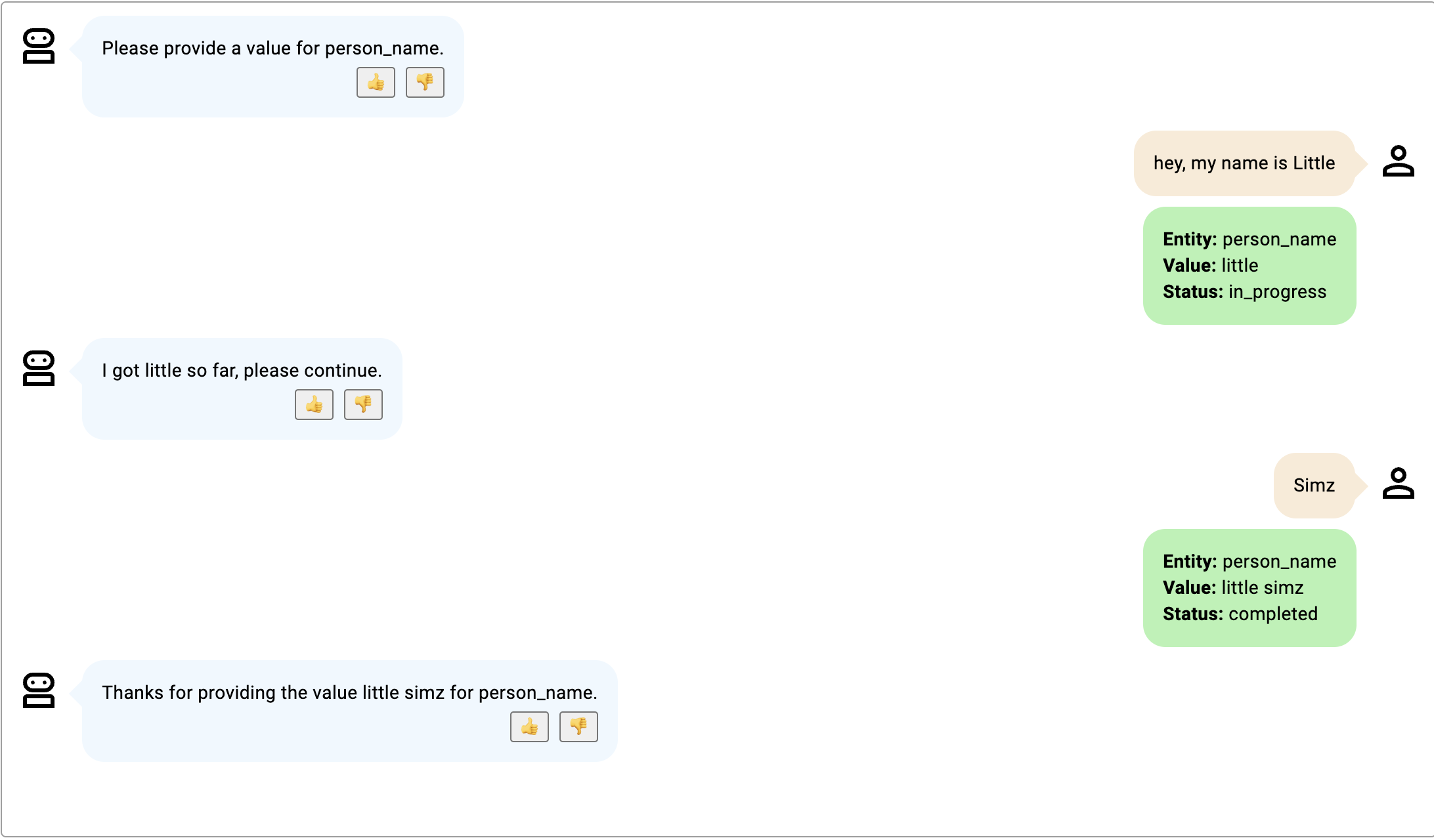
- Les deux sous-entités sont fournies en même temps et le statut devient complété après le premier tour.
Cliquez sur l’image pour l’agrandir.
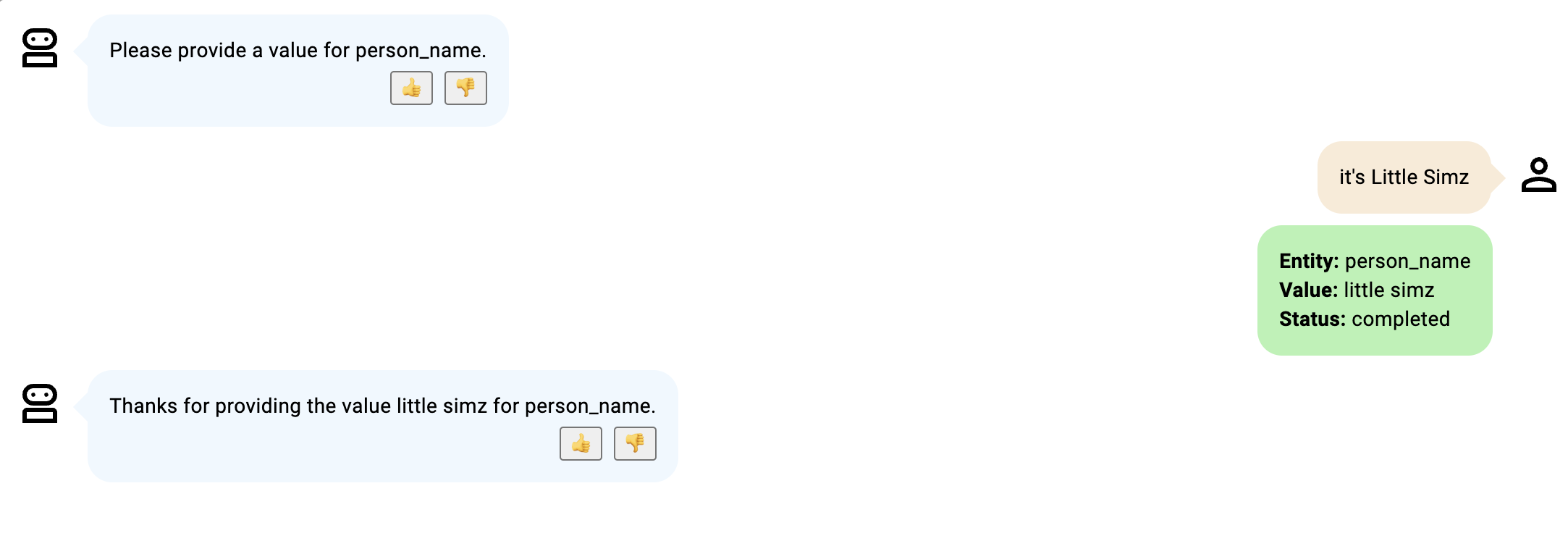
- Le statut reste en cours parce que le bot participant précise que l'entité fournie est un deuxième prénom, non mentionné dans la description ; la prochaine entité fournie par le bot participant est supposée être le nom de famille, comme prévu.
Cliquez sur l’image pour l’agrandir.
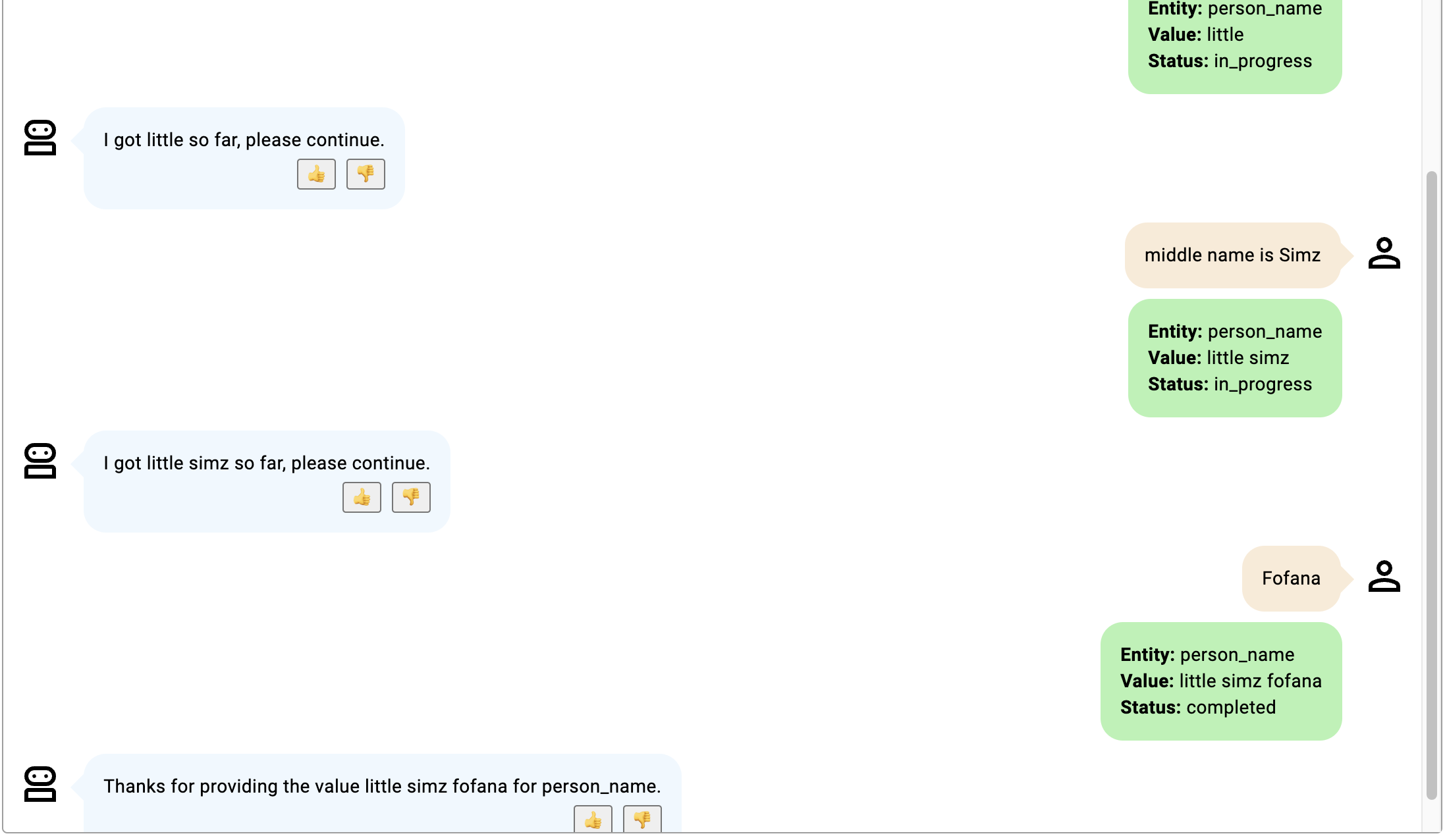
- Bien que le participant au robot ne le précise pas et que l'on puisse supposer que "van der" est un nom de famille, ce n'est probablement pas le cas, car "van der" est un préfixe de nom de famille couramment utilisé et non un nom de famille réel.
Cliquez sur l’image pour l’agrandir.
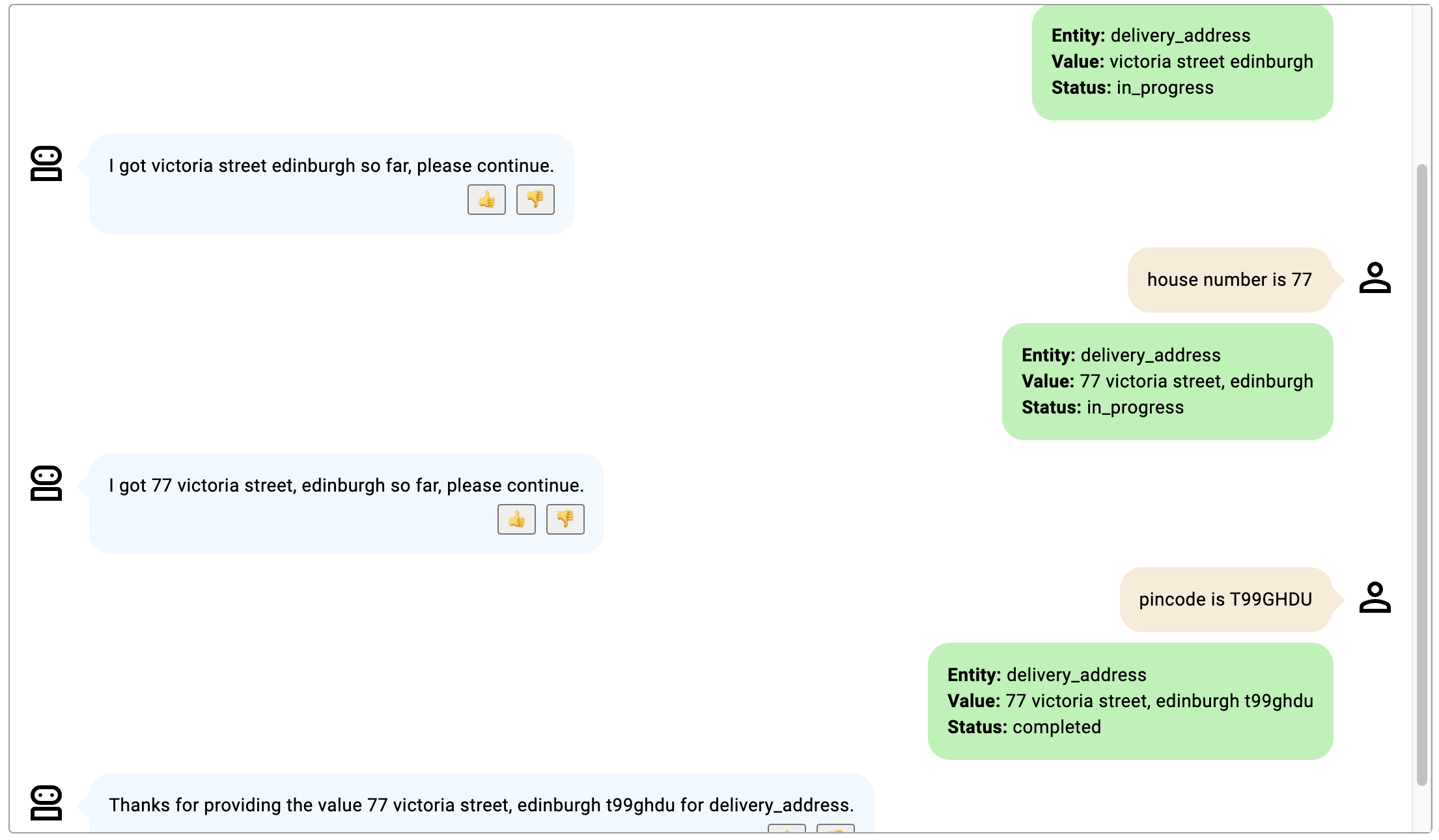
Dans ces exemples, l'emplacement est delivery_address pour décrire une adresse de livraison comprenant le numéro de maison et le code PIN.
- La conversation se poursuit jusqu'à ce que le numéro d'habitation et le code PIN soient fournis ; le numéro d'habitation est ajouté au début de l'adresse et le code PIN à la fin.
Cliquez sur l’image pour l’agrandir.
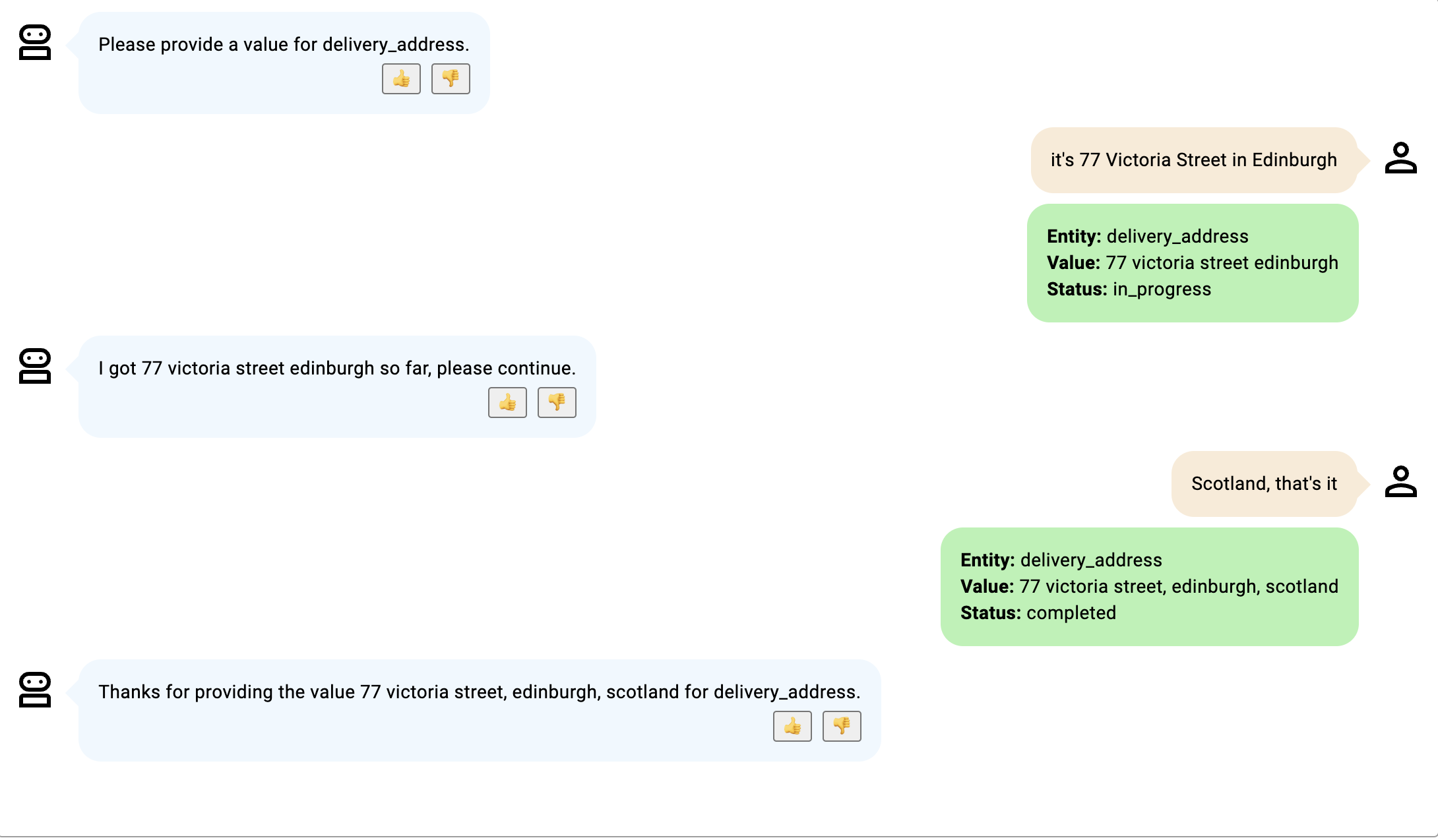
- Bien qu'aucun code PIN n'ait été fourni, le statut devient terminé car le participant au robot indique qu'il a terminé. Ce statut n'apparaît pas lorsque le participant ne dit pas "c'est tout" et le statut ne devient "terminé" que lorsqu'un code PIN est fourni.
Cliquez sur l’image pour l’agrandir.
Exemples de créneaux libres : Comportement de sortie anticipée
Ces exemples décrivent des scénarios de sortie anticipée pour un slot delivery_address qui décrit une adresse de livraison avec un numéro de maison et un code PIN.
- Exemple 1 Exemple de sortie anticipée
Cliquez sur l’image pour l’agrandir.
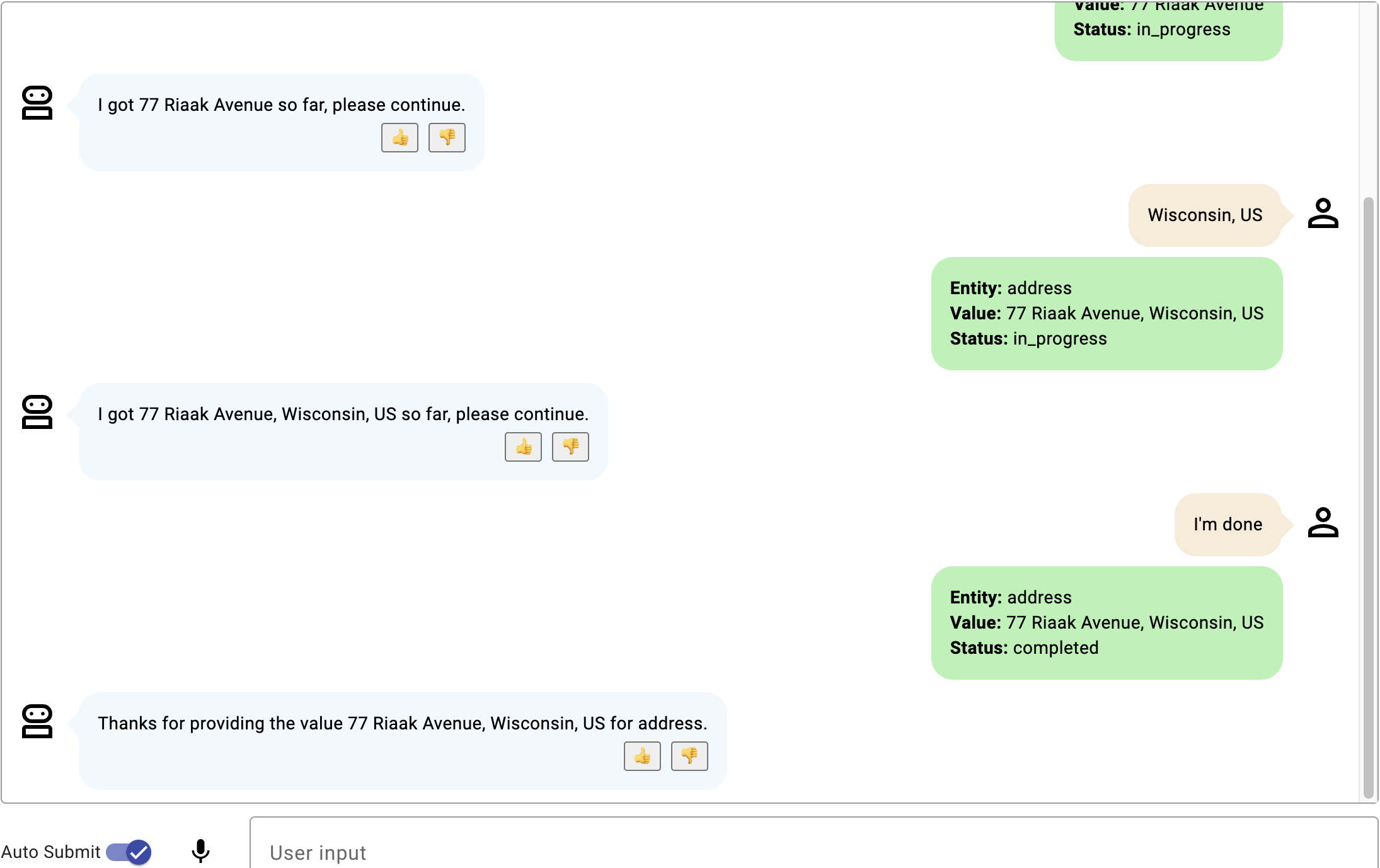
- Exemple 2 Exemple de sortie anticipée.
Cliquez sur l’image pour l’agrandir.
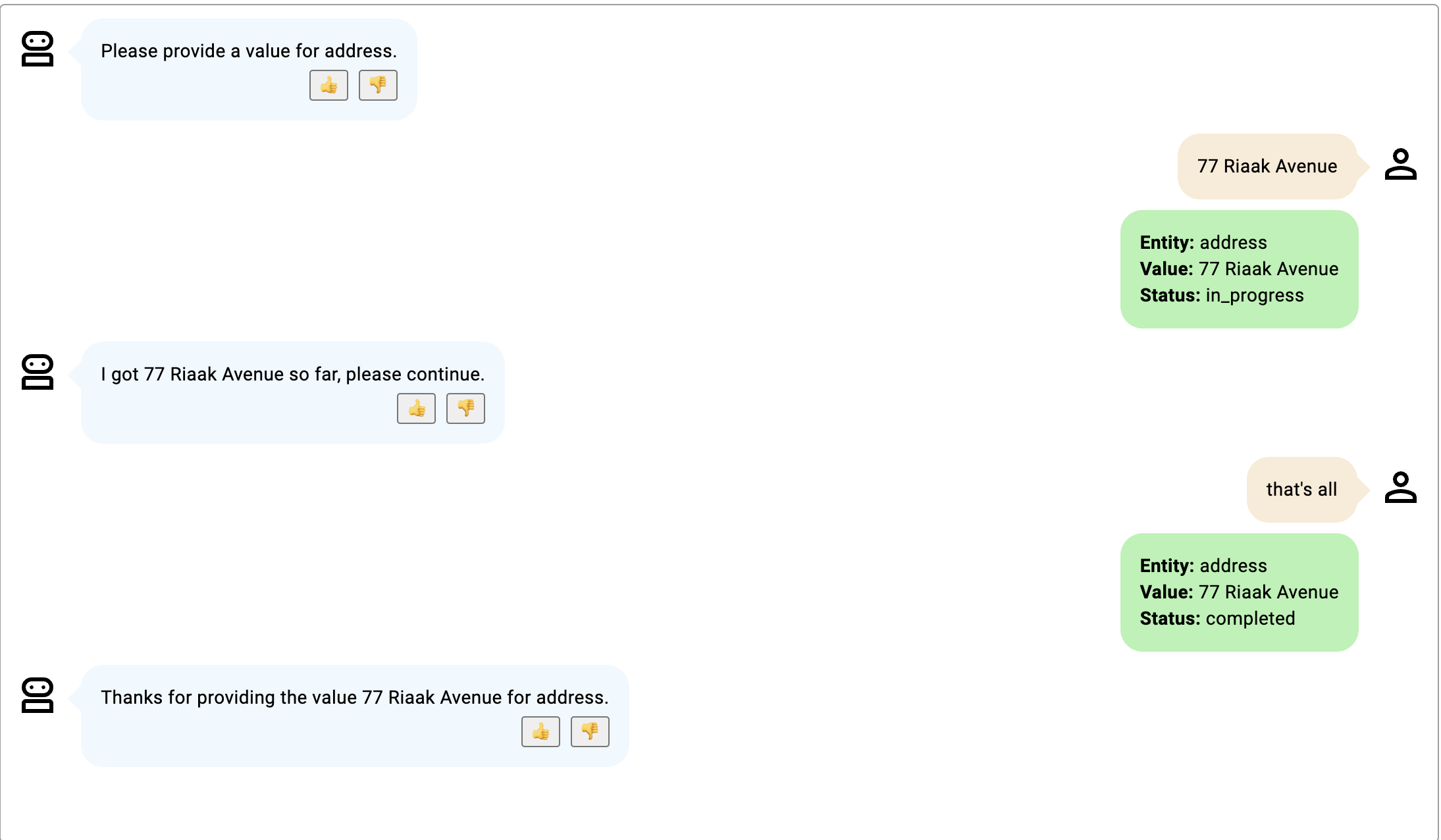
- Exemple 3 Exemple de sortie anticipée.
Cliquez sur l’image pour l’agrandir.

- Exemple 4 Exemple de sortie anticipée.
Cliquez sur l’image pour l’agrandir.

Pour plus d'informations sur les exemples de conversations qui illustrent le fonctionnement de la capture de créneaux libres, voir Exemples de capture de créneaux libres.
Considérations générales
- La qualité de l'extraction des créneaux dépend de la qualité de la transcription de l'audio en texte dans le canal vocal. Le concept "garbage in, garbage out" s'applique ici car les erreurs de transcription se propagent.
- Le message d'invite au client doit mentionner que l'entité peut être fournie en une ou plusieurs fois.